Appearance
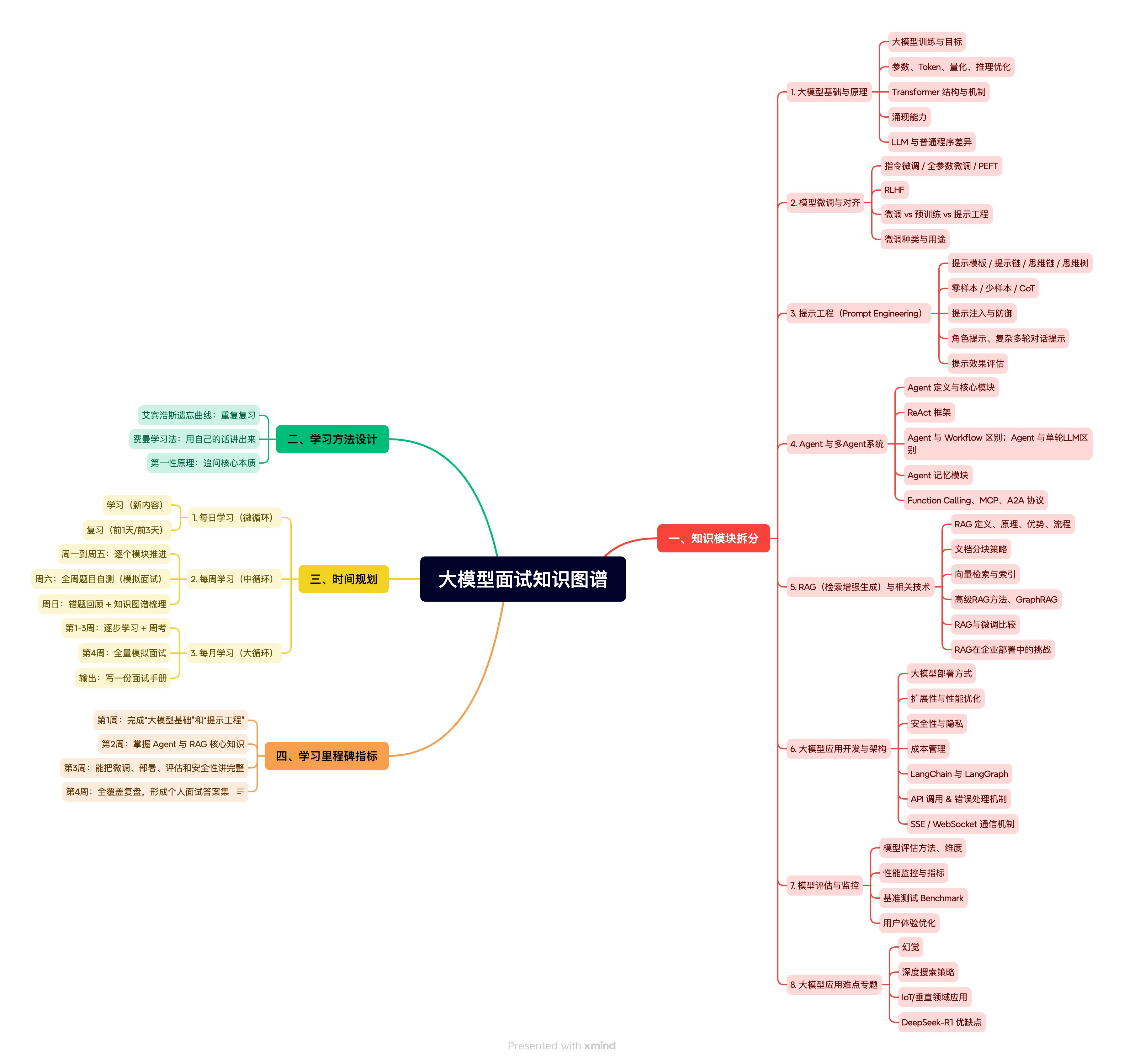
一、知识模块拆分
1. 大模型基础与原理
大模型训练与目标
参数、Token、量化、推理优化
Transformer 结构与机制
涌现能力
LLM 与普通程序差异
2. 模型微调与对齐
指令微调 / 全参数微调 / PEFT
RLHF
微调 vs 预训练 vs 提示工程
微调种类与用途
3. 提示工程(Prompt Engineering)
提示模板 / 提示链 / 思维链 / 思维树
零样本 / 少样本 / CoT
提示注入与防御
角色提示、复杂多轮对话提示
提示效果评估
4. Agent 与多Agent系统
Agent 定义与核心模块
ReAct 框架
Agent 与 Workflow 区别;Agent 与单轮LLM区别
Agent 记忆模块
Function Calling、MCP、A2A 协议
5. RAG(检索增强生成)与相关技术
RAG 定义、原理、优势、流程
文档分块策略
向量检索与索引
高级RAG方法、GraphRAG
RAG与微调比较
RAG在企业部署中的挑战
6. 大模型应用开发与架构
大模型部署方式
扩展性与性能优化
安全性与隐私
成本管理
LangChain 与 LangGraph
API 调用 & 错误处理机制
SSE / WebSocket 通信机制)
7. 模型评估与监控
模型评估方法、维度
性能监控与指标
基准测试 Benchmark
用户体验优化
8. 大模型应用难点专题
幻觉
深度搜索策略
IoT/垂直领域应用
DeepSeek-R1 优缺点
二、学习方法设计(结合三大原则)
艾宾浩斯遗忘曲线:重复复习 → 1天/3天/7天/14天/30天节点。
费曼学习法:每个模块学习后,用自己的话讲出来,像对面试官/同事解释。
第一性原理:每个概念都问自己“它最核心的本质是什么?为什么要这样设计?如果不这样会怎样?”
三、时间规划
1. 每日学习(微循环)
学习:1–2 小时
新内容:1 个子模块(约 5–7 道题目)
方式:看题 → 自己回答 → 查资料补充 → 用费曼法讲解
复习:30 分钟
前 1 天的内容(短期记忆回顾)
前 3 天的内容(巩固)
👉 指标:能用口头表达清楚,解释时逻辑自洽,无明显卡壳。
2. 每周学习(中循环)
周一到周五:逐个模块推进
周六:全周题目自测(模拟面试),每题限时 2 分钟回答
周日:错题回顾 + 知识图谱梳理(绘制思维导图,把模块连起来)
👉 指标:80% 题目能在 2 分钟内答出核心要点。
3. 每月学习(大循环)
第 1–3 周:逐步学习 + 周考
第 4 周:全量模拟面试(100+ 题,分模块随机抽问)
输出:写一份面试手册(题目 + 自己的简洁答案)
👉 指标:
至少 3 次完整模拟面试演练
答案结构:先定义 → 再机制/原理 → 最后应用/优缺点
四、学习里程碑指标
第1周:完成“大模型基础”和“提示工程”,能清晰解释 Transformer 机制和 Prompt 技巧。
第2周:掌握 Agent 与 RAG 核心知识,能讲清楚它们的流程与区别。
第3周:能把微调、部署、评估和安全性讲完整,答题时有结构感。
第4周:全覆盖复盘,形成个人面试答案集。
五、大语言模型面试知识图谱
六、支持作者
如果这个项目对你有帮助,欢迎赞助支持!
你的支持是我继续优化和更新项目的动力,让更多人受益于优质的LLM学习资源。

支付宝赞助

微信赞助
感谢每一位支持者,你们的鼓励是我持续更新的动力!🚀