Appearance
本资料参照李宏毅老师所讲解的Transformer整理而来。
0. Transformer 架构
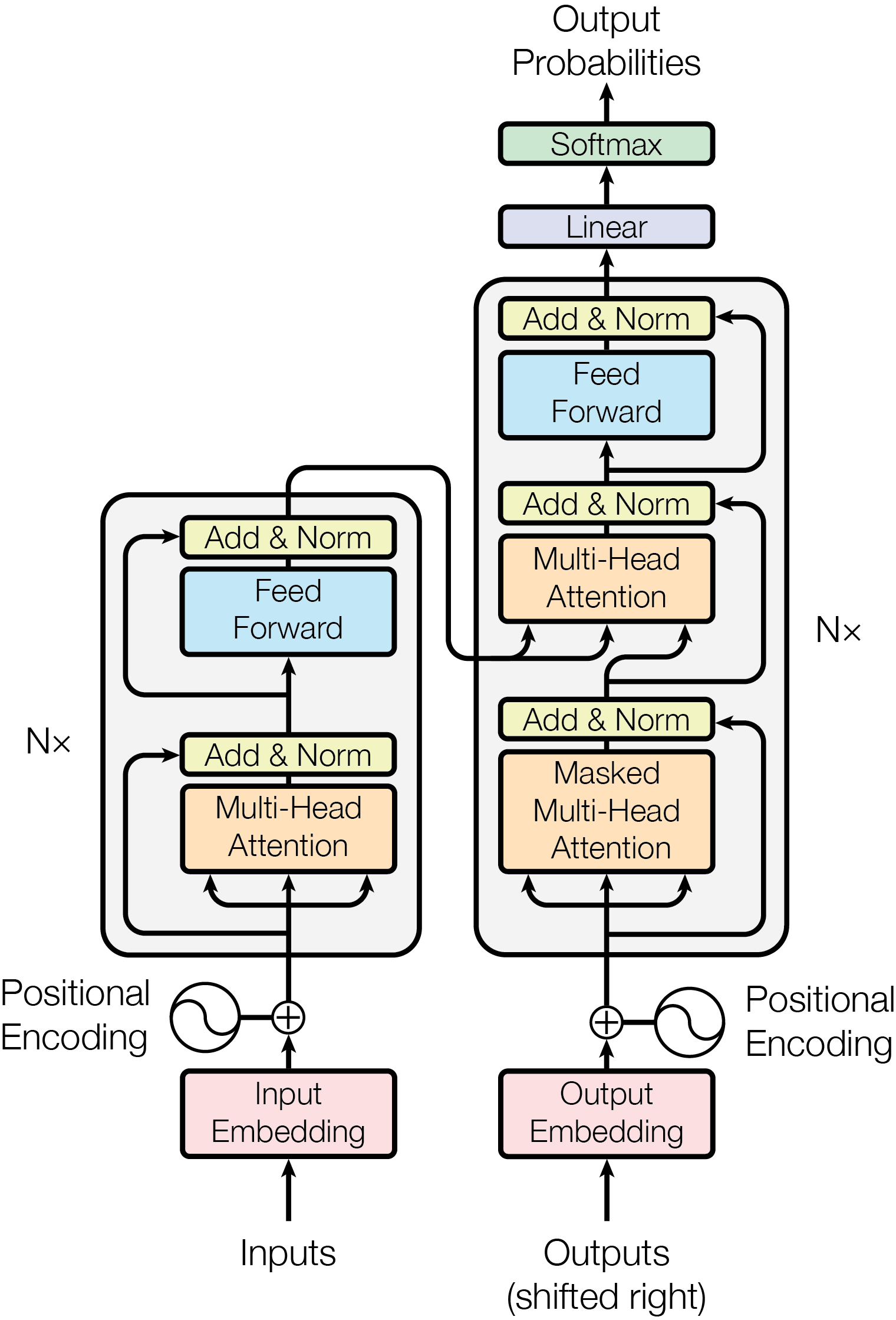
Transformer 模型的结构和原理
- 基本概念
- Transformer 是当前大型语言模型的基础架构之一,由谷歌团队在2017年提出 。
- Transformer 的核心思想是基于自注意力机制(Self-Attention)来建模序列,而不采用RNN的递归结构。
- 其衍生出两种架构,BERT 和 GPT,ChatGpt 等大模型就是基于 GPT的。
- 其基本结构可以分为编码器(Encoder)和解码器(Decoder)两个堆叠模块,不过很多语言模型(GPT系列)只用解码器部分。
- 结构和原理介绍
- 输入嵌入和位置编码:
- 首先,输入的序列(如一句话)经过嵌入层得到词向量表示。
- 由于Transformer没有像RNN那样的顺序处理,自身不感知序列顺序信息,因此加入位置编码(正余弦位置编码):即生成一个和嵌入维度相同的向量,其各维按词位置n以不同频率的sin/cos函数赋值。
- 这些位置向量加到词嵌入上,使得模型能区分第1个词还是第10个词 。
- 多头自注意力层(Multi-Head Self-Attention):
- 这是Transformer的核心组件。对于输入序列的一组表示,它通过“注意力”机制让每个位置的表示去参考序列中其他位置的信息。
- 具体来说,自注意力将输入X通过线性变换得到查询向量Q、键向量K、值向量V,然后计算注意力权重
。 - Transformer的创新在于多头(Multi-Head):它并行执行多组独立的注意力计算(通常8或16头),每组有自己的投影矩阵Q,K,V,捕获不同子空间的相关性,然后将各头结果拼接后再线性变换。这让模型能关注不同关系特征,比如某一头专注于句法依存,另一头关注语义关联等。
- 前馈网络(Feed-Forward Network, FFN):
- 紧随注意力层之后,每个Transformer子层还有一个全连接前馈网络,通常包含通常包含两个线性变换层和一个在中间的非线性激活层(如ReLU) 。
- 在自注意力捕获到全局信息之后,进行局部维度上的非线性加工与变换,帮助模型提炼更复杂的语义表示。
- Transformer交替叠堆多头注意力和前馈网络。
- 残差连接和层归一化:
- 每个子层(注意力或FFN)都有残差连接(input直接加到output)和层归一化操作。
- 这保证深层网络的梯度传递稳定,并加速收敛 。
- 输入嵌入和位置编码:
- 整体来看,一个典型Transformer block = Multi-head Attention + Residual + Norm + FFN + Residual + Norm。Encoder由N个block叠加;Decoder类似但在注意力部分多一个跨注意力。
- Transformer相较传统RNN的优势
- 并行计算
- RNN循环依赖上一步输出,无法并行处理序列。
- 而Transformer的自注意力机制对序列中每个位置同时计算与其他位置的相关性,没有时序依赖,可以用矩阵运算并行处理整句话 。
- 这使得训练时GPU利用率高,能够在海量数据上训练非常深的模型。
- 长程依赖捕获
- 注意力机制可以让每个词直接“看”其他所有词,不管距离多远都在一次注意力计算中体现。
- 而RNN要经过许多步状态传递才能把远处信息带过来,中间可能梯度消失或信息淡化。
- 更好的表示能力:
- 多头注意力提供了对不同关系特征的建模能力,且注意力是输入内容自适应的,加上FFN的非线性变换,整个模型具有极强表达力。
- RNN虽然也可以堆叠层和门控,但Transformer因为摆脱了序列顺序计算限制,可以更自由地增加层数和宽度(维度),加上FeedForward层提供丰富特征组合,因而更易扩展出超高参数模型。
- 训练稳定性:
- Transformer用了注意力+残差+正则化,使其训练较稳定。
- 某些RNN需要小心初始化和梯度剪裁,以避免梯度消失和爆炸问题。
- 梯度爆炸(gradient explosion):训练刚开始,Loss 一下子飙升为无穷大;
- 梯度消失(gradient vanishing):Loss 长期不下降,模型几乎不学习。
1. 什么是Transformer?
Seq2seq model with "Self-attention"
Transformer 是一个将 Seq2seq 思想推向极致的模型。它巧妙地利用自注意力、残差连接和层归一化等技术,解决了传统模型在处理序列数据时的核心痛点,成为了现代自然语言处理领域最重要的基石之一。
这里给大家一个网站 先直观的感受下Transformer架构
2. 为什么 Transformer 是带自注意力机制的 Seq2seq 模型?
Transformer 模型用自注意力机制 完全替代了早期 Seq2seq 模型中的循环结构(如 RNN)。
它的编码器 使用了多个自注意力层,每个层都能让输入序列中的每个词同时考虑其他所有词的信息。
它的解码器 也使用了自注意力层,它不仅能关注到自身已经生成的词,还能通过“交叉注意力”机制,关注到编码器处理后的输入序列信息。
因此,可以说 Transformer 是对 Seq2seq 架构的一种革命性改进,它用强大的自注意力机制解决了序列处理中的核心问题,实现了更高效、更强大的序列到序列转换。
3. Encoder 的设计哲学
Transformer 革命性地抛弃了传统的循环神经网络(RNN),完全使用 自注意力机制 来构建,从而实现了并行化计算,极大地提高了训练效率。
Encoder 的核心作用:输入一排向量,输出另一排等长的向量,用于捕捉输入序列的特征。
Encoder 的详细结构解析:
位置编码 (Positional Encoding):这是 Transformer 的关键设计。由于自注意力机制是并行处理的,无法感知词语的顺序。因此,需要在输入向量中加入位置信息,告诉模型每个词在序列中的位置。
多头自注意力(Multi-Head Self-Attention):这是 Encoder 的第一个子层。它不是一个单一的自注意力,而是同时运行多个“头”,每个头都从不同角度去关注序列中词语之间的关系。这种多头的并行计算能捕捉更丰富的语义信息。
残差连接 (Residual Connection):这是深度学习中一个非常重要的设计模式。在每个子层(如自注意力层或前馈网络)之后,都会将子层的输入直接加到输出上,形成“输入 + 子层输出”的新向量。这能有效解决深层网络训练中常见的梯度消失问题,让模型可以堆叠得更深。
层归一化 (Layer Normalization):残差连接后会进行层归一化。这是一种归一化方法,与批归一化(Batch Normalization)不同。
Batch Normalization:针对一个批次内所有样本的同一个特征维度进行归一化。
Layer Normalization:针对同一个样本内的所有特征维度进行归一化。老师特别提到,在 Transformer 中,层归一化的效果通常优于批归一化。
前馈网络(Feed Forward Network):这是 Encoder 的第二个子层。它是一个简单的全连接网络,用于对自注意力的输出进行非线性转换,然后再次进行残差连接和层归一化。
重复堆叠:整个 Encoder 由多个这样复杂的 Block 重复堆叠而成。老师指出,BERT 模型就是由 Transformer 的 Encoder 部分构建的。
为何是这样的设计?
Layer Normalization 的位置:原始 Transformer 论文中的 Layer Normalization 是放在残差连接之后。但有研究表明,将其位置稍微调整(例如放到每个 Block 的输入端),效果可能会更好。
选择 Layer Norm 的原因:为什么 Transformer 选择了 Layer Norm 而不是 Batch Norm?除了效果更好外,Layer Norm 不依赖于批次大小,这使得模型训练更稳定,尤其是在使用小批次时。
4. Decoder 的内部结构(与Encoder的异同)
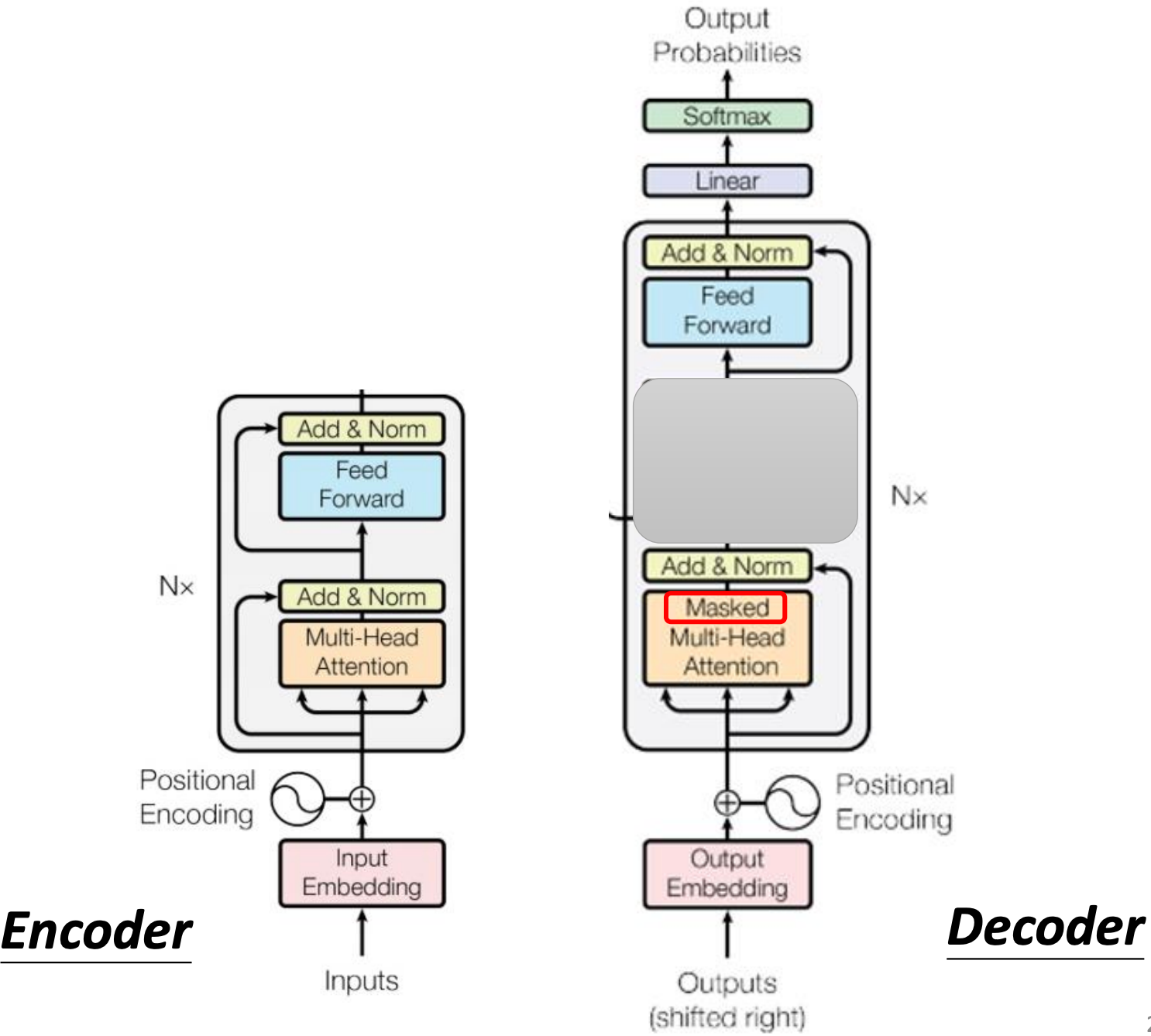 Transformer 的 Decoder 负责根据 Encoder 的输出,逐步生成目标序列。
Transformer 的 Decoder 负责根据 Encoder 的输出,逐步生成目标序列。
Decoder 的两种类型:
Autoregressive (AT) Decoder:逐字生成。这是最常见的方式,每一步的输出都作为下一步的输入,直到生成
<EOS>结束符。Non-Autoregressive (NAT) Decoder:并行生成。它能一次性生成整个序列,速度更快,但通常性能稍逊于 AT Decoder,且需要额外的机制来决定输出长度。
Autoregressive (AT) Decoder 的详细结构:
与 Encoder 的相似之处:Decoder 的基本结构与 Encoder 类似,都包含“注意力层”和“前馈网络”,并使用残差连接和层归一化。
关键差异:Decoder 的 Block 中间多了一个 Cross Attention 层,且最前面的 Self Attention 必须是 Masked。
遮蔽自注意力 (Masked Self-Attention):这是为了模拟真实推理时的逐字生成过程。在训练时,它强制模型在预测当前词时,只能看到它前面已经生成的词,而不能“偷看”后面的词。
交叉注意力 (Cross Attention):这是连接 Encoder 和 Decoder 的桥梁。它允许 Decoder 在生成每个词时,从 Encoder 的输出中抽取相关信息。Decoder 提供 Query,Encoder 提供 Key 和 Value,通过计算 Query 和 Key 的注意力分数,来加权求和 Encoder 的 Value,从而得到新的上下文向量。
5. 训练与推理的实用技巧
不仅适用于 Transformer,也适用于其他 Seq2seq 模型。
强制教学 (Teacher Forcing):
原理:在训练时,将正确的标准答案作为 Decoder 的输入。这能加速模型学习。
问题:这会导致 Exposure Bias。在测试时,Decoder 看到的是自己上一步的错误输出,这可能导致“一步错,步步错”的问题。
解决方法:Scheduled Sampling 技术在训练时偶尔给 Decoder 错误的输入,让它学会如何处理错误。
束搜索 (Beam Search):
原理:一种比贪婪解码 (Greedy Decoding) 更优的推理策略。它在每一步都会保留多个最佳候选序列,而不是只选择一个,从而尽可能地找到全局最优路径。
适用性:对于答案明确的、唯一的任务(如语音辨识),束搜索通常很有用;但对于需要创造力的任务(如写故事),加入随机性反而能得到更好的结果。
复制机制 (Copy Mechanism):
原理:让模型除了从词汇表中选词,还能直接从输入序列中复制词语到输出中。
适用性:在对话或摘要等任务中非常有用,可以避免模型错误地生成或遗漏专有名词。
引导式注意力 (Guided Attention):
原理:在一些任务(如语音合成)中,注意力权重的移动模式应该是有规律的(如由左向右)。如果模型没有学到,则会出错。
作用:在训练中强制注意力遵循特定的模式,保证输出的正确性和流畅性。
强化学习 (RL) 训练:
问题:训练时优化的损失函数(如交叉熵)与最终评估指标(如 BLEU Score)不一致。
解决:将生成过程视为一个强化学习问题,直接将 BLEU Score 作为奖励 (Reward) 来进行优化。
6. Attention 和 Self-Attention的区别是什么?
Attention和Self-Attention的主要区别在于它们处理的信息来源不同:
- Attention:
传统的Attention机制发生在Source元素和Target的中的所有元素之间。
在Encoder-Decoder框架中,输入Source和输出Target通常内容不一样, 例如在机器翻译中,Source是英文句子,Target是对应的中文句子。
Attention是通过一个查询变量Q找到V里面重要信息,K由V变换而来
- Self-Attention:
Self-Attention指的是Source内部元素之间或者Target内部元素之间发生的Attention机制。
相当于是Query=Key=Value,但实际上是X通过Wk、Wq、W^v线性变换得到QKV
在Transformer中,只需要在Source处进行对应的矩阵操作,用不到Target中的信息
- 总结区别:
- Self-attention关键点在于规定K-Q-V三者都来源于同一个输入X,通过X找到X中的关键点
- Self-attention比attention约束条件多了两个:
- Q、K、V同源(都来自于同一个输入)
- Q、K、V需要遵循attention的计算方法
7. Transformer 中的 Self-Attention 公式是什么?
Self-Attention 的核心计算公式可以用以下 LaTeX 代码表示:
其中:
(Query), (Key), (Value) 是通过输入序列 与对应的权重矩阵相乘得到的: 是 Key 向量的维度,缩放因子 用于防止点积结果过大导致 softmax 梯度消失。 函数在 的序列维度上进行归一化,生成注意力权重。
8. 为什么要除以
- 计算点积时,如果Q、K的元素值和
的值都很大,那么点积的结果可能会非常大,导致softmax函数的输入变得非常大。softmax函数在处理很大的输入值时,会使输出的概率分布接近0或1,这会造成梯度非常小,难以通过梯度下降有效地训练模型,即出现梯度消失问题。 - 通过使用
缩放点积的结果,可以使点积的数值范围被适当控制,从而: - 防止softmax函数进入饱和区域
- 保持梯度在合理范围内
- 使训练更加稳定
- 这种缩放操作是基于Q和K的元素是均值为0、方差为1的随机变量的假设,此时它们点积的方差将是dk,通过除以
可以将方差重新归一化为1。
9. Transformer 的 Encoder 和 Decoder 结构分别包含哪些子层?
- Encoder结构:
- Encoder由六个相同层堆叠而成,每层包含两个子层:
- 多头自注意力层(Multi-Head Self-Attention):允许模型关注输入序列的不同位置
- 前馈神经网络层(Position-wise Feed-Forward Network):由两个线性变换组成,中间有ReLU激活函数,形式为:Linear + ReLU + Dropout + Linear
- 每个子层都使用残差连接(Residual Connection)和层归一化(Layer Normalization)
- Encoder由六个相同层堆叠而成,每层包含两个子层:
- Decoder结构:
- Decoder也由六个相同层堆叠而成,每层包含三个子层:
- 带掩码的多头自注意力层(Masked Multi-Head Self-Attention):确保预测位置i时只能依赖于小于i的位置的输出
- 多头注意力层(Multi-Head Attention):对Encoder的输出进行注意力计算,也称为Encoder-Decoder Attention
- 前馈神经网络层(Position-wise Feed-Forward Network):与Encoder中的相同同样,每个子层都使用残差连接和层归一化
- Decoder也由六个相同层堆叠而成,每层包含三个子层:
10. Encoder 端和 Decoder 端是如何进行交互的?
Encoder 端和 Decoder 端通过 Cross Self-Attention(也称为 Encoder-Decoder Attention)机制进行交互。
具体过程如下:
- Encoder 处理输入序列,生成一系列编码表示(上下文向量)
- 在Decoder 的第二个子层(多头注意力层)中:
- Decoder 提供 Q(查询向量):来自 Decoder 前一层的输出
- Encoder 提供 K 和 V(键向量和值向量):来自 Encoder 最终层的输出
- 这允许 Decoder 的每个位置都能关注到输入序列的所有位置
这种交互机制使得Decoder能够在生成输出时,根据已生成的部分和输入序列的完整信息来决定下一个输出,从而实现序列到序列的转换。
在机器翻译等任务中,这种机制使得模型能够在生成目标语言的每个词时,关注源语言中的相关部分,实现更准确的翻译。
11. Transformer的优缺点是什么?
- 优点:
- 可并行计算:不像RNN需要按序列顺序处理,Transformer可以并行处理整个序列,大大提高了训练效率
- 解决长距离依赖问题:通过自注意力机制,模型可以直接建立序列中任意两个位置之间的联系,有效捕获长距离依赖关系
- 独立于卷积和循环:完全依赖于attention处理全局依赖,架构更简洁
- 性能强大:在多种NLP任务上取得了突破性的性能提升
- 可解释性:注意力权重可以提供模型决策过程的一定解释性
- 缺点:
- 输入长度固定:标准Transformer模型有固定的最大序列长度限制
- 计算复杂度高:自注意力机制的计算复杂度是O(n²),其中n是序列长度,对于长序列计算成本高
- 局部信息的获取不如RNN和CNN强:Transformer关注的是全局关系,而RNN在计算过程中更关注局部,对距离更加敏感
- 位置信息需要额外编码:不像RNN天然包含序列顺序信息,Transformer需要额外的位置编码
- 训练数据需求大:需要大量数据才能充分发挥性能
- 预训练计算资源需求高:大型Transformer模型的预训练需要大量计算资源
12. 为什么 Transformer 中使用多头注意力机制(Multi-Head Attention)?
Transformer 使用多头注意力机制(Multi-Head Attention)的主要原因有:
- 增强模型的表达能力:
- 不同的注意力头可以关注输入序列的不同方面和特征
- 例如,某些头可能关注语法关系,而其他头可能关注语义关系
- 并行学习不同的表示子空间:
- 多头机制将查询、键和值投影到不同的子空间
- 这允许模型同时从不同的表示空间学习信息
- 增加注意力的稳定性:
- 多个头的结果被合并,减少了单一注意力机制可能带来的噪声和不稳定性
- 类似于集成学习中的"多个弱学习器组合成强学习器"的思想
- 捕获更丰富的上下文关系:
- 单一注意力机制可能只能捕获一种类型的依赖关系
- 多头机制可以同时捕获多种类型的依赖关系,如短距离和长距离依赖
- 提高模型的鲁棒性:
- 即使某些头的注意力分布不理想,其他头仍可能提供有用的信息
- 这种冗余性提高了模型的整体鲁棒性
在实践中,多头注意力通常比单头注意力表现更好,特别是在复杂的序列转换任务中。标准Transformer使用8个头(对于encoder和decoder)。
13. 为什么 Transformer 中使用 Layer Normalization 而不是Batch Normalization?
Transformer 使用 Layer Normalization(LN) 而不是 Batch Normalization(BN) 的原因主要有:
- 序列长度不一致问题:
- NLP任务中,不同样本的序列长度通常不同
- BN需要在批次维度上计算统计量,当序列长度不一致时,这变得复杂且不稳定
- LN对每个样本独立进行归一化,不受序列长度差异影响
- 批量大小限制:
- 由于Transformer模型较大,训练时通常只能使用较小的批量大小
- BN在小批量上的统计估计不准确,性能会下降
- LN不依赖批量统计,对批量大小不敏感
- 序列特性考虑:
- NLP中认为句子长短不一,且各batch之间的信息没有什么关系
- LN只考虑句子内信息的归一化,更适合NLP任务特性
- 位置不变性:
- LN对序列中的所有位置应用相同的归一化参数
- 这与Transformer处理序列的方式更加一致
- 训练稳定性:
- 实践表明,在Transformer架构中,LN提供了更好的训练稳定性
- 特别是在深层网络中,LN有助于缓解梯度消失/爆炸问题
总结来说,BN和LN的主要区别在于归一化的维度不同:BN是对一批样本的同一维度特征做归一化,而LN是对单个样本的所有维度特征做归一化。在Transformer这类处理变长序列的模型中,LN更为适合。
14. Transformer中的自注意力计算复杂度是多少?有哪些方法可以降低复杂度?
标准自注意力的计算复杂度:
- 时间复杂度:O(n²·d),其中n是序列长度,d是表示维度
- 空间复杂度:O(n²),主要来自于注意力矩阵的存储
降低复杂度的方法:
- 稀疏注意力(Sparse Attention):
- 不计算所有位置对之间的注意力,而是选择性地计算部分位置对
- 例如,局部注意力只计算相邻位置的注意力
- 代表工作:Sparse Transformer、Longformer
- 低秩近似(Low-Rank Approximation):
- 使用低秩矩阵近似完整的注意力矩阵
- 可以将复杂度降低到O(n·r),其中r是秩的大小
- 代表工作:Linformer
- 核方法(Kernel Methods):
- 使用核函数近似softmax操作
- 避免显式计算完整的注意力矩阵
- 代表工作:Performer、Linear Transformer
- 局部敏感哈希(Locality-Sensitive Hashing):
- 使用哈希技术将相似的查询和键分组
- 只在相同哈希桶内计算注意力
- 代表工作:Reformer
- 滑动窗口注意力(Sliding Window Attention):
- 每个位置只关注固定窗口内的其他位置
- 复杂度降低到O(n·w),其中w是窗口大小
- 代表工作:Longformer、Big Bird
- 分块注意力(Blocked Attention):
- 将序列分成固定大小的块,先计算块内注意力,再计算块间注意力
- 代表工作:Big Bird、ETC
- 递归方法(Recursive Methods):
- 使用递归结构处理长序列
- 代表工作:Transformer-XL、Compressive Transformer
- 线性注意力(Linear Attention):
- 重写注意力计算公式,使复杂度变为线性
- 代表工作:Linear Transformer、Performer
这些方法各有优缺点,选择哪种方法取决于具体应用场景、序列长度和计算资源限制。最新的研究持续探索更高效的注意力机制,以处理更长的序列。
15. 什么是Transformer中的多头注意力(Multi-Head Attention)?它是如何计算的?
在 Transformer 中,注意力机制(Attention)是用来衡量一个序列中不同位置之间的相关性。
多头注意力(Multi-Head Attention, MHA) 的核心思想是:
不是只用一个注意力函数,而是用 多个注意力头(Heads) 并行去计算,然后把结果拼接起来。
这样做的好处是:
每个头可以关注输入序列的不同子空间(不同特征)。
模型可以并行学习多种关系,例如:句法关系、语义关系、长距离依赖等。
假设输入是一个长度为
1. 线性映射生成 Q,K,V
通过可学习的矩阵,把输入 X 映射为 Query (Q)、Key (K)、Value (V):
其中:
2. 缩放点积注意力 (Scaled Dot-Product Attention)
单个注意力头的计算公式为:
这里
3. 多头并行计算
假设有 h 个头,每个头都有自己的参数矩阵
则第 i 个头的输出为:
4. 拼接并线性变换
把所有头的输出拼接起来,再做一次线性映射:
其中:
- 多头注意力的核心公式:
作用:
并行捕捉不同特征子空间的依赖关系
提升模型的表达能力
稳定训练
16. Transformer 的训练和推理阶段有什么区别?
Transformer在训练和推理阶段有几个关键区别:
- 解码过程:
- 训练阶段:
- 采用"教师强制(Teacher Forcing)"方式
- Decoder一次性接收完整的目标序列作为输入
- 所有位置的输出可以并行计算
- 使用序列掩码(Sequence Mask)确保每个位置只能看到之前的位置
- 推理阶段:
- 采用自回归(Autoregressive)方式
- Decoder每次只生成一个新token
- 生成过程是顺序的,不能并行
- 每生成一个新token,都会将其添加到已生成序列中,然后预测下一个token
- 注意力计算:
- 训练阶段:
- Encoder的自注意力可以完全并行计算
- Decoder的自注意力也可以并行计算(但有序列掩码限制)
- 计算效率高
- 推理阶段:
- Encoder的自注意力仍然可以并行计算
- Decoder的自注意力需要逐步计算
- 可以使用缓存(KV Cache)存储之前计算的键值对,避免重复计算
- 批处理:
- 训练阶段:
- 可以高效地处理大批量数据
- 所有样本的长度通过填充统一
- 推理阶段:
- 通常批量大小较小,甚至为1
- 生成长度可能不固定,取决于停止条件
- 计算效率:
- 训练阶段:
- 高度并行化,GPU利用率高
- 固定的计算图,可以优化
- 推理阶段:
- 顺序生成导致GPU利用率较低
- 动态计算图,优化空间有限
- 内存使用:
- 训练阶段:
- 需要存储完整的计算图和梯度
- 内存需求高
- 推理阶段:
- 不需要存储梯度
- 可以使用KV缓存优化
- 内存需求相对较低
- 停止条件:
- 训练阶段:
- 处理固定长度的目标序列
- 长度由训练数据决定
- 推理阶段:
- 使用特殊的结束符号(EOS)或最大长度限制
- 生成过程动态决定何时停止
这些区别导致Transformer在训练时可以高效并行,而在推理时则面临效率挑战,这也是为什么许多研究致力于提高Transformer推理效率的原因。
17. Transformer 中的残差连接 (Residual Connection) 和层归一化 (Layer Normalization) 的作用是什么?
1. 残差连接 (Residual Connection)
在 Transformer 中,每个子层(比如 多头注意力 或 前馈网络 FFN)的输入
作用:
缓解梯度消失/梯度爆炸
- 残差让梯度可以绕过非线性层,直接传递到前面层,使得深层网络也能训练。
信息保留
- 输入信息不会在经过子层时完全丢失,而是保留到下一层,保证模型在学习新特征的同时保留原始特征。
加速收敛
- 避免“退化问题”(网络层数增加反而性能下降),提升优化效率。
2. 层归一化 (Layer Normalization, LN)
LayerNorm 是在 每个样本的特征维度上做归一化。
假设某一层输入向量为
其中
作用:
稳定训练过程
- 保证不同层输入分布比较稳定,避免梯度不稳定。
加快收敛
- 减少了对学习率的敏感性。
提升泛化能力
- 归一化让模型对输入分布的变化更鲁棒。
3. 残差 + 层归一化在 Transformer 中的结合
在 Transformer 的标准实现(Vaswani 等人的原始论文)中,每个子层结构为:
这就是所谓的 “Add & Norm”。
作用:
残差保证了信息传递和梯度流动
LayerNorm 保证了数值稳定和训练收敛
两者结合让模型既能学到复杂特征,又能避免训练不稳定
总结
残差连接:让输入信息和梯度直接传递,缓解深层网络训练困难。
层归一化:保持数值稳定,提升收敛速度和泛化能力。
Add & Norm 是 Transformer 稳定高效训练的关键设计。
18. Transformer中为什么使用Q、K、V三个矩阵,而不是直接使用自身进行注意力计算?
1. 直接使用输入做注意力会有局限性
假设输入是矩阵
如果直接用
这样每个 token 之间的相关性只来自 原始 embedding 空间,模型无法根据任务灵活地选择不同的“视角”去建模。
2. Q、K、V 提供了不同的角色
通过可学习的投影矩阵
各自的作用:
Query (Q):表示“我要找什么信息”
Key (K):表示“我能提供什么信息”
Value (V):表示“实际要传递的信息内容”
注意力分数的计算:
然后用这个分数加权 Value:
这样,模型可以灵活地“问—答—取值”:
Q 提问
K 回答是否相关
V 提供真正的信息
3. 可学习的子空间投影
都是 可学习参数。 它们把输入映射到不同的 子空间,让不同的注意力头能学习到不同的特征关系。
如果没有 Q、K、V 的投影,所有注意力只能在原始 embedding 空间中学习,表达能力会大打折扣。
4. 多头注意力的基础
在 Multi-Head Attention 中,每个头都有不同的
这样:
Head1 可能专注于 语法关系(如主谓一致)
Head2 可能专注于 语义关系(如同义替换)
Head3 可能专注于 长距离依赖
这种灵活性就是由 Q、K、V 提供的。
总结
Transformer 使用 Q、K、V 的原因是:
解耦角色:Query 表示“查找需求”,Key 表示“可匹配特征”,Value 表示“携带信息”。
增强表达能力:通过投影到不同子空间,让模型能灵活捕捉不同的关系。
支持多头机制:不同头通过不同的 Q、K、V 投影来关注不同的特征。
避免局限性:直接用输入
计算会限制模型只能在原始 embedding 空间建模,缺乏灵活性。
19. Transformer 中的位置编码 (Positional Encoding) 有什么作用?如何实现的?
1. 位置编码的作用
在 Transformer 中,输入序列被表示为一组向量
注意力机制本身是 对输入顺序无感的,因为计算
只依赖向量之间的相似度,而不包含位置信息。
如果没有位置编码,Transformer 就无法区分
- “I love you” 和 “You love I”
因为它们的词向量集合是一样的。
所以 位置编码的作用就是显式注入序列顺序的信息。
2. 位置编码的实现方式
(1)固定位置编码(Sinusoidal Positional Encoding)
Vaswani 等人在《Attention is All You Need》中提出了 正弦余弦函数编码:
其中:
表示位置(0,1,2,...,n) 表示维度索引 是模型的维度
特点:
不需要学习参数
任意长度的序列都能编码(具有外推性)
不同位置的编码有规律性,便于模型学习相对位置信息
(2)可学习的位置编码(Learnable Positional Embedding)
另一种方法是把位置当成一个“单词”,给每个位置学习一个可训练向量:
这样位置编码和词向量一样,作为参数参与训练。
特点:
灵活,能更好适配具体任务
但外推性差(超过训练长度的序列可能无法泛化)
3. 使用方式
最终输入 Transformer 的向量是:
也就是 词向量 + 位置编码 相加,得到既包含语义信息,又包含位置信息的表示。
4. 总结一下
作用:在无顺序感的注意力机制中引入位置信息
实现:
正弦余弦位置编码(固定,不需训练,能泛化到长序列)
可学习的位置编码(参数化,更灵活,但泛化性差)
结合方式:将位置编码与词向量逐元素相加
20. Transformer中的前馈神经网络(Feed-Forward Network)有什么作用?
1. FFN 的定义
在 Transformer 中,每个位置(token)经过多头注意力后,会再通过一个 位置前馈神经网络 (Position-wise Feed-Forward Network, FFN):
其中:
:单个位置的向量表示 ,通常 (比如 512 → 2048 → 512) 激活函数通常是 ReLU 或 GELU
注意:这个 FFN 是 逐位置 (position-wise) 独立计算 的,也就是说,不同 token 各自通过同一个 FFN 变换,不会互相影响。
2. FFN 的作用
提升特征表达能力
多头注意力负责建模 不同 token 之间的依赖关系,但每个 token 自身的特征变换能力有限。
FFN 通过非线性变换,增强了每个 token 的表示能力,使模型能学习更复杂的模式。
增加模型的深度和非线性
单纯的注意力是线性加权求和,不够强大。
加上 FFN(带激活函数)后,模型才具备深层非线性网络的表达力。
扩展维度 (Projection & Bottleneck)
FFN 通常会先把维度扩展到更高的
,再压缩回来。 这样可以提供更大的“计算空间”,类似 CNN 中的 1x1 卷积瓶颈结构。
位置独立的特征变换
注意力机制处理的是“跨位置的交互”,FFN 处理的是“单位置的特征映射”。
两者结合,就能同时学习 全局依赖 和 局部特征变换。
3. 在 Transformer 中的位置
每个 Encoder / Decoder Layer 里,结构是:
也就是在 多头注意力之后,再接一个 FFN,形成 Attention + FFN 的模块,层层堆叠。
4. 总结
FFN 公式:
作用:
增强 token 表示的非线性和表达力
提供更大维度的计算空间(Projection + Bottleneck)
补充注意力机制的不足(注意力关注“跨 token”,FFN 关注“单 token”)
设计理念:和多头注意力互补,使模型既能学习全局关系,也能学习局部特征
21. Transformer的解码搜索策略是什么?为什么需要它?
Transformer 是自回归生成模型,即:一步步生成下一个 token,每一步都依赖前面的上下文输出。每一步生成时,会有很多个候选词,解码策略决定了选择哪一个token 最好
解码策略对比
- Greedy Search 贪婪搜索
- 每一步只选取概率最高的词
- 快速,简单
- 容易局部最优而不是全局最优,容易输出模版化内容
- Beam Search 集束搜索
- 定义
- 是一种启发式宽度优先搜索策略,目的是在保证计算效率的前提下,找到可能性最高的输出序列,精度和效率介于贪婪和穷举之间
- 原理
- 设置Beam Width(束宽度)= k:每一步保留 k 个累计概率最优的候选序列作为路径,其余全部剪枝
- 下一步对现有的k个路径扩展新的token,此时有k x V个候选,再从中选新的 top-k,做为新的k个路径,然后再次扩展。
- 时间复杂度O(k V L) 空间复杂度O(k L)
- k:束宽度 V:候选token L:最大路径长度
- 可以探索更多组合,质量通常优于greedy
- 计算开销大,多样性低
- 定义
- Top-k Sampling(限制采样)
- 每步随机从 top-k 个高概率词中采样
- 使生成回答具有一定的创意,并且可以降低幻觉
- Top-p Sampling
- 不固定个数,而是只采样概率达到 p(如0.9)的词
- 更加动态和灵活
解码策略种类
- 确定性解码
- Greedy、Beam Search
- 可复现
- 适合翻译、摘要
- 优点是稳定、高质量
- 缺点是乏味、模板化
- 随机性解码
- Top-k Sampling、Top-p Sampling
- 不可复现
- 适合写作、对话
- 优点是多样、有创意
- 缺点是有幻觉、会偏离主题